A while back I decided to train a language model from scratch. Not fine-tune one. Not LoRA-adapt one. Train one - weights initialized to noise, tokenizer built from my own corpus, the whole thing.
The reason was simple and slightly irrational: I wanted to understand what was actually happening inside these things. Not at the API level. Not at the "here's how attention works" blog post level. At the "it's 2 AM and the loss curve is doing something weird" level.
Why did I use the Polish language?
I'm Polish. I wanted a model that could handle Polish text natively, not as an afterthought grafted onto an English-dominant tokenizer that wastes 3–4 tokens per word with diacritics. Polish has ą, ć, ę, ł, ń, ó, ś, ź, ż - a Latin-script language, but one that most tokenizers treat as exotic. From a practical point of view, Polish is a rich language with flexible word order and noun declension across seven cases. The same verb root can produce dozens of surface forms. If a model can learn to handle this, it's doing something closer to real generalization. Those characteristics of the Polish language (and “yours truly” native Polish speaker status) made it a genuinely interesting training target. And Polish is hard.
The architecture
I built a GPT-style transformer. Decoder-only, autoregressive, the standard recipe. The specific configuration I settled on:
- Decided on 1.3B parameters not to kill my GPU
- 28 layers should be enough for my learning
- 1536 embedding dimensions
- 16 attention heads
- Finally - the context window: 1024 tokens (consumer GPU, memory-limited)
Nothing exotic. The architecture itself is well-understood at this point - the interesting problems are elsewhere: data, tokenization, training stability, and just keeping the thing running on hardware that wasn't designed for this.
The consumer hardware reality
I trained this on an RTX 4070 at home. 12 GB VRAM. Consumer GPUs are great, but they have their own limitations, which are evident in both memory availability and training speed (they could at least have more CUDA cores). A 1.3B-parameter model in FP32 requires roughly 5.2 GB to store the weights. Add optimizer states (Adam keeps two momentum buffers per parameter - another ~10 GB in fp32), gradient accumulation, activations - you're well past what fits. So you use FP16 mixed precision and gradient checkpointing, and you accept that batches will be small.
I used what was popular at that time - DeepSpeed ZeRO-2, which shards optimizer states across devices. With a single GPU, you don't get the distributed memory savings you'd get across a cluster, but it still helps with memory efficiency, the tooling is solid, and, most importantly, it allows me to learn. ZeRO-2 keeps parameters and gradients on each device but partitions the optimizer state, meaning the Adam moments for each parameter live in a single logical place rather than being duplicated. Effective batch size matters a lot for language model training. With a single 12 GB card, I was stockpiling gradients across many micro-batches to simulate larger effective batches. Slow. But it works.
Then I started training…
~51 epochs. Final loss: ~2.345. and it was worth it. In the meantime I built AIP tool to visualize this progress not to get mad looking at ugly log - you can read about it on my LinkedIn here: I’m excited to share AIP, a lightweight tool I’ve been building in Go to bring sanity to my LLM model training process...
Compared to GPT-2 small (117M params), trained on WebText, it achieves a perplexity of around 2.85 on its validation set. My loss of 2.345 corresponds to perplexity of roughly e^2.345 ≈ 10.4 - meaning the model assigns, on average, roughly equal probability to about 10 plausible next tokens at each position. For a 1.3B model trained on complex Polish data, that's reasonable. It's not GPT-4. It's also not random noise.
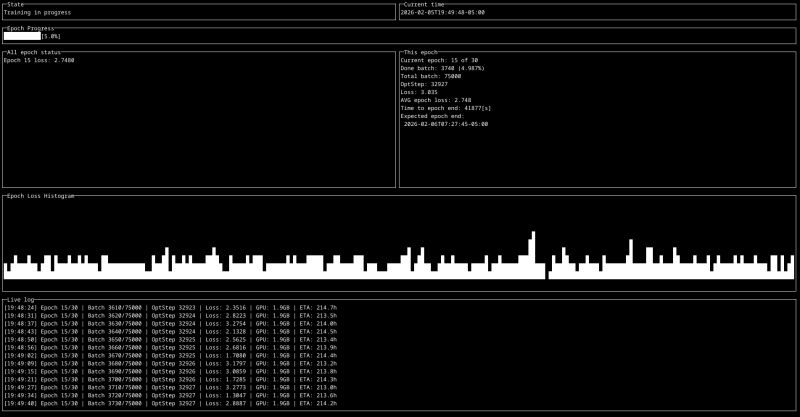
With AIP I was monitoring loss curves, GPU utilization, estimated time remaining, and samples from the current checkpoint. I spend a lot of time staring at loss curves when training takes days, and having a real dashboard rather than grep-ing log files makes the difference between catching a problem early and discovering it at epoch 40.
The loss curve behaved well for the first ~30 epochs - steady descent, occasional spikes that recovered. Around epoch 35, things flattened out. I reached a point where the model had seen the data enough times that further exposure produces diminishing returns, and I was essentially just watching the optimizer micro-adjust around a local minimum.
What I learned from people who'd done this professionally?
I didn't figure all of this out in isolation - I had friends who also build ML models, they as always gave me a helping hand (and critical judgment when I did something stupid). Before going down this rabbit hole on my own, I'd spent time working alongside people who were shipping real ML products at scale. Contracting for Pearson Education, I worked on two products that put me in proximity to teams doing this seriously:
-
One was an AI-based calculus tutor - handwritten text to full calculus solution tutor, who was teaching you how to solve complex calculus equtions step by step, explaining what, when and where. Full multi-model ML pipeline that made researchers and me I worked with sweat. It was great!
-
The other was an AI-based English tutor with chat and live calling capabilities - real-time conversation, voice processing, and capaibilites to fix your english accent in no time. Another product ahead of its time.
What I absorbed from those teams wasn't specific architecture tricks. It was something more fundamental: how to think about the gap between a model that works in a notebook and a model that ships. Data quality as a first-order concern. Evaluation harnesses that test what the product actually needs to do, not just perplexity on a held-out slice. The discipline of understanding where your model fails before your users do. That thinking shaped how I approached my own training run. I built evaluation into the process from the start rather than treating it as an afterthought.
Final judgement: what a 1.3B Polish model can and can't do
1.3B parameters is not a lot by current standards and that was visible. The model generated plausible-sounding Polish text. It handled morphological agreement reasonably well. It produced sentences that a native speaker would recognize as syntactically coherent. It does not reason, do not understand the language construction. It does not have reliable factual knowledge. It hallucinates comfortably and without apparent shame.
Still the point was to build something I could interrogate. When I looked at attention patterns, I was looking at my model's attention patterns - trained on data I'd assembled, with a tokenizer I'd built, with hyperparameters I'd chosen and tuned. That's a different kind of understanding than you get from calling an API.
The portability
One thread I kept pulling on: Go inference. Python owns the ML training stack for good reason - PyTorch, JAX, the whole ecosystem lives there. But Python is not where I want to be at inference time on constrained hardware.
I explored porting a trained PyTorch model to a Go inference server via llama.cpp and CGO. llama.cpp's GGUF format is well-suited to this - it supports quantization levels from fp16 down to 2-bit, which dramatically changes the memory footprint. A 1.3B model in Q4_0 quantization sits around 700 MB. That fits on a Raspberry Pi. That fits on an edge device.
The CGO bridge worked. It's not elegant, but it's functional - and the performance at inference time in Go is predictable in a way that Python runtimes are not.
That's also the reason in Purple I did used Ollama as backend instead of reinventing the wheel by myself. Because once I did.
Would I do it again
Yes, and many times I was thinking about it, but I'm limited in time. By current standards, a 1.3B parameter model is fairly humble but training your own model from scratch forces you to understand things I could not learn any other way. I learn what loss curves feel like when training is healthy versus when something is wrong. I learned why learning rate schedules matter and what happens when you don't warm up, what happens when you don't decay. I also learned that "data quality" is not an abstract principle but a very concrete problem with very concrete symptoms in the loss curve.
And I end up with something that is entirely mine.
~Matt