Ollama-powered Purple Backend: Bringing LLMs to Your Workflow
The landscape of Local Large Language Models (LLMs) has undergone a massive transformation, and at the heart of this shift is Ollama. For developers building applications like Purple—a tool designed to streamline creative AI workflows—Ollama isn't just an option; it's becoming foundational infrastructure. But what does using Ollama mean for model deployment, and how does it give you true freedom in your development environment?
What is Ollama?
❯ ollama ls
NAME ID SIZE MODIFIED
gemma4:e4b c6eb396dbd59 9.6 GB 10 days ago
qwen2.5-coder:14b 9ec8897f747e 9.0 GB 11 days ago
nomic-embed-text:latest 0a109f422b47 274 MB 12 days ago
gemma4:26b 5571076f3d70 17 GB 12 days ago
gemma4:12b 4eb23ef187e2 7.6 GB 12 days ago
gemma4:31b-cloud c382fbfbc73b - 2 weeks ago
gemma4:e2b 7fbdbf8f5e45 7.2 GB 2 weeks ago
llama3.2-vision:11b 6f2f9757ae97 7.8 GB 3 weeks ago
qwen3.5:9b 6488c96fa5fa 6.6 GB 8 weeks ago
At its core, Ollama operates much like a package manager or runtime environment (think of Docker) but specifically optimized for managing and running machine learning models. It provides a simple, standardized infrastructure for models that can run locally on your computer, whether that's through a powerful desktop setup or even a dedicated server instance.Crucially, Ollama allows you to manage various open-source models (like Llama 3, Mistral, etc.) without needing deep knowledge of CUDA, containerization registries, or complex environment variables. It abstracts the complexity away, allowing developers to focus purely on integration and application logic—in our case, powering features within Purple.
Mobility and Model Freedom: Beyond Local Hardware Limits
A common narrative surrounding powerful local tools is the "either/or" fallacy: either you run exclusively locally on a beefy machine, or you rely entirely on the cloud. This viewpoint often overlooks the core concept of mobility.
Some critics argue that an emphasis on local models means a limitation to customers who possess high-end hardware (like cards with substantial VRAM). While it is true that running the largest and most demanding models locally requires significant GPU power, this perspective ignores the value proposition when combined with cloud access.
Our real goal, and the strength of the Purple backend integration, is achieving continuity: You want a seamless workflow whether you are at your powerful workstation at home or developing on limited hardware away from the house.
The Power of Hybrid Backends (Local vs. Cloud)
Imagine this scenario: You develop complex AI-driven workloads for Purple at home, utilizing your dedicated local Ollama deployment connected to your most powerful machine. Everything works perfectly—models run instantly and privately through your home network.
Now, you are away from home, working on a co-working setup or even developing late at night on an older laptop (say, that non-RTX-grade MacBook Air). You don't want your development pipeline to break down just because your local hardware isn't up to the task of running massive models. With the architecture powered by Ollama and Purple’s backend logic, you can simply switch the configuration:
At Home: The workflow defaults to your powerful local Ollama instance. On the Go: The workflow seamlessly switches to accessing a managed, external cloud model endpoint provided through Ollama's infrastructure.
Or even different scenario - you want to test high-capabilities model you would not be able to deploy at your existing GPU. Ollama cloud lets you do that.
The application (Purple) remains consistent. You experience zero degradation in user flow or required code changes—you just gain robust operational flexibility.
Understanding Cloud Costs and Commitment
While Ollama offers a free tier for its services, it is vital to remember that access to high-quality cloud models is not inherently "free."
When you are using a remote service, someone (or some infrastructure) is running the computations: they are consuming electricity, maintaining hardware, and managing cooling. These costs must be covered somewhere. I strongly encourage users to understand this cost structure and consider subscribing when your usage volume or required model performance necessitates continuous cloud access.
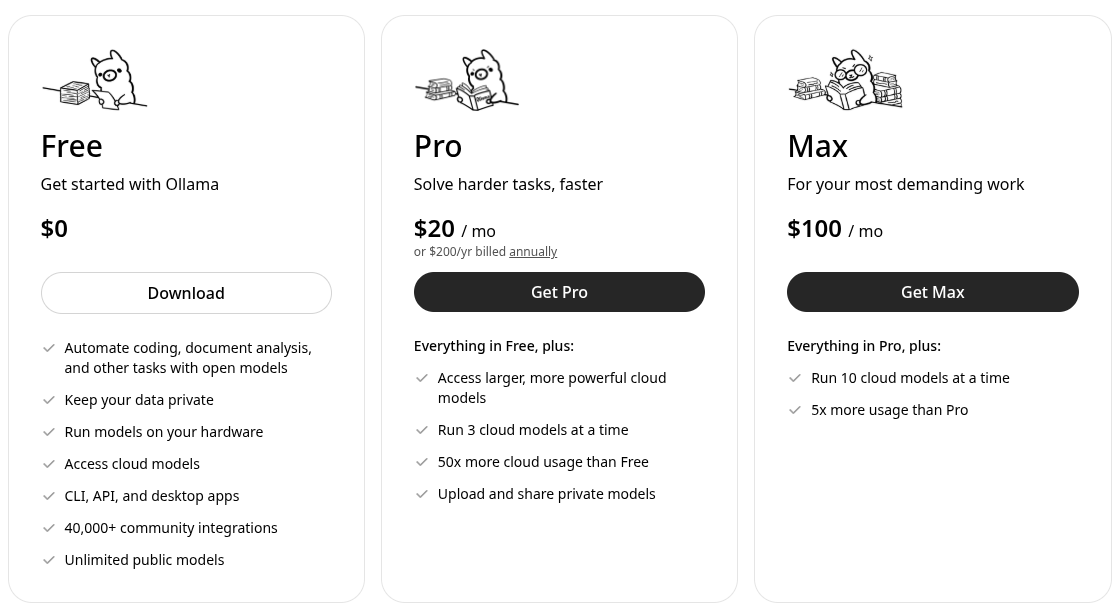
Paying for the subscription isn't just paying for convenience; it's contributing directly to the continued operation of their AI compute infrastructure.
The Future is Universal Access
Before judging Ollama or any local-first approach, we must look at the overall business use case: liberation. We are all fighting for the same thing—the ability to use advanced AI models without being locked into a single vendor, region, or piece of hardware.
By integrating Ollama both locally and providing robust cloud options, Purple achieves this perfect balance.Introducing cloud access is not saying "abandon local model running." Instead, it says: **"We are giving a tool—a full-featured workflow platform—to people who do not have the required dedicated hardware to run demanding models at all."

Ollama powers Purple by making LLMs accessible, predictable, and infinitely portable. It ensures that your creative vision can run equally well from your powerful desk setup or while you are on a coffee shop network miles away.